Google Flu Trends: Grossly misleading or misunderstood science?
Published 29 Mar, 2014 14:57 | Updated 29 Mar, 2014 14:57
Google’s revolutionary Flu Trends system, which purports to predict outbreaks with startling precision, has been slowly derailing over the years, giving faulty information because of its flawed algorithms, scientists have found.
The wonder of this statistical engine lay in the promise that it would track flu outbreaks in real-time, promising to usher in a new era in disease prevention and a further synergy of humanity with technology. It worked by pooling search terms together to create an accurate picture of where the sickness is, how serious it is, and how many people in the area are infected. This would give doctors and the pharmaceutical industry advance warnings on outbreaks.
However, it has been found that the GFT prediction system has been going more and more off track in the past couple of years. It was overestimating flu impact increasingly, until, finally, in February 2013 it forecast twice as many occurrences of flu than had actually happened.
A team led by Professor David Lazer of the Harvard Kennedy School in the US has carried out a study, concluding that GFT routinely overestimated flu occurrences when the system was compared to the data seen in organizations whose manual accumulation of it dates back decades.
In a study, published in the journal Science, Lazer’s team outlines several problems. Among the more important ones are the following: that such data, as given by Google, will necessarily be flawed because, unlike the Center for Disease Control and Prevention (CDC) – on who’s historically recorded data GFT was based, it is “a predictive model of future CDC reports about the present," as the Guardian found out from speaking with Lazer; and that spotting these flaws is nearly impossible, unless one were to specifically look for them.
Also, when Google first introduced GFT in 2009, it outlined how “certain search terms are good indicators of flu activity,” which clearly illustrated to them the relationship between searching for flu-related topics and people actually having flu. But Lazer’s team note that correlation is far from an indicator of causality.
So, in sum, too much trust was being placed in an inherently flawed statistical model.
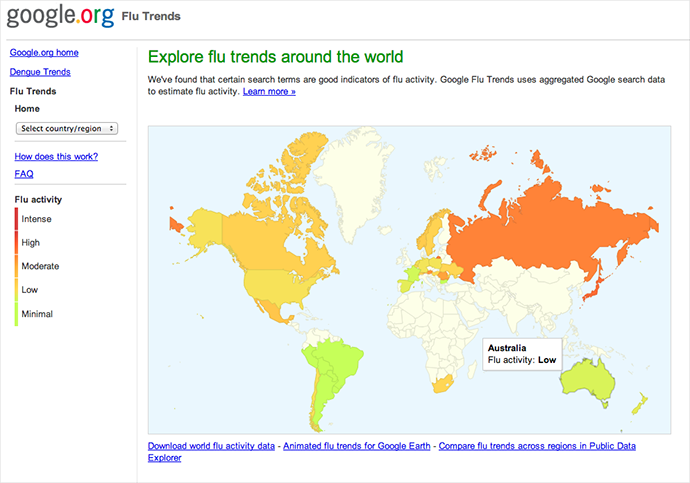
GFT’s troubles started since its inception in 2008, the team believes. And shortly thereafter, Google also introduced the ‘autosuggest’ – a feature that estimates what one searches for based on the cumulative statistics of past searches, and offers ready-made suggestions. The conflict between ‘big’ and ‘small data’ was apparent to Lazer. ‘Big data’ is the science of predicting trends based on integrating sets of data with unstructured data. ‘Small data’ is information small enough for human comprehension – basically, big data crunched into small, workable categories).
Lazer notes that, while the algorithm of correlating 50 million search terms with 1,152 data points is sound, the incidence of registering likely search terms that were actually completely unrelated to having flu, “were quite high.” Google’s methods of picking applicable search terms are not known to anyone but them.
The company has made attempts at rectifying this issue with regular updates in the way that it presents its health-related information to searchers – but what that seems to have done is get people more focused on what Google is willing to offer in terms of flu treatment, as opposed to listening to the actual problem.
And increasingly the searched terms were more correlated with established GFT patterns, as opposed to CDC data. This slowly steered GFT away from being an accurate tool.
Moreover, changes made to the algorithm (which Google doesn’t reveal) most likely have a Pavlovian effect on the user and coax them into searching increasingly for things that Google wants to show them. But Lazer also points out that groups of people tend to change ways in which they do things in time as well even without changes to the search algorithm. The test data on which Google Flu Trends is built comes from searches performed over 10 years ago – a lot could have changed since.
Moreover, as time passes, people got naturally predisposed to being comfortable with the auto-suggest feature, and that, again skews data by making people search for the first thing that pops up.
The most important lesson Lazer’s team has extracted from their study is that “you have to build and maintain a mode like this based on the assumption that these types of relationships are elastic – there is no natural constant here like pi – and constantly, or regularly, recalibrate.”
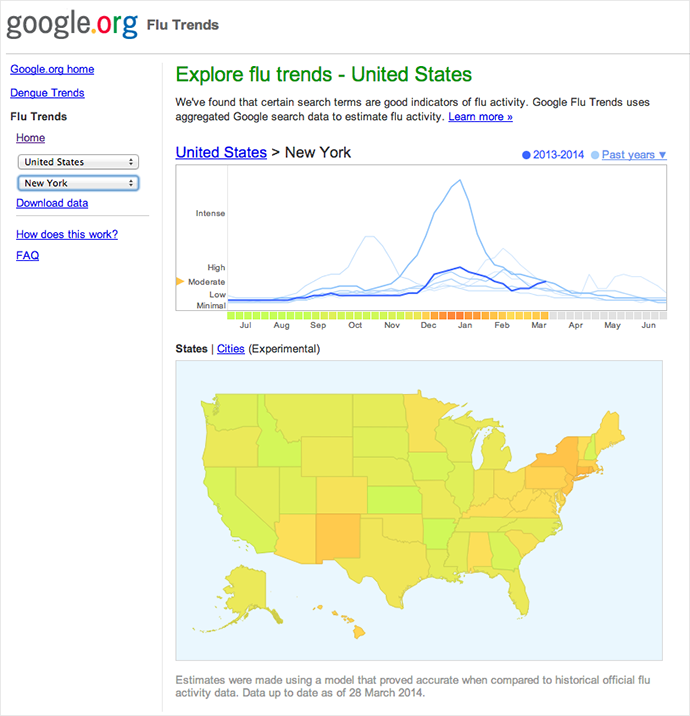
Lazer’s arguments, however, also support the idea of GFT – like the fact that when its results are combined with lagged CDC statistics, influenza prediction actually became more accurate than both monitoring systems.
And some would argue that a negative outlook on GFT is also quite pessimistic for not taking into account how any technological, big-data developments in disease monitoring are actually a good thing regardless; as well as the fact that all data systems based on correlating unstructured data are imperfect.
Craig Dalton, who coordinates the program, FluTracking, is someone whose own project uses Google Trends data to compare it to Australian databases, as well as its own predictions. All the way back in 2008, Dalton was excited about the then-new system.
“We saw a very striking correlation between the rise in the Google influenza related search data throughout August and our Flutracking.net data, which compares the rate of cough and fever among influenza vaccinated and unvaccinated participants.”
When speaking to the Sydney Herald presently, he defended Google by saying that there are a number of factors that lead to information being skewed: like people being increasingly told to get tested during peak infection periods – especially when that peak period came during the rather violent H1N1 pandemic of 2009, when GFT was still in its infancy. Google had at first omitted the non-standard words associated with the outbreak and had to soon recalibrate its algorithms. The point Dalton makes is that the service does become better every time it does so.
When Dalton was invited by Google to their office in 2010 to test out improvements in GFT, he said they were quite visible. In a late 2013, Google publicly admitted to its overestimations. They said it was because of a spike in media coverage, which caused searches to spike.
"Many studies coming out and attacking Google Flu Trends I think are flawed themselves. It has an incredibly important place in the whole suite of data trends that support flu monitoring," he told the Australian newspaper.