'Compact & durable’: Scientists encode, retrieve 10,000 gigabytes stored on DNA molecules
Researchers at the University of Washington and Microsoft are developing one of the first complete storage systems to house digital data in DNA. The news comes as the digital universe is expected to hit 44 trillion gigabytes by 2020.
“Life has produced this fantastic molecule called DNA that efficiently stores all kinds of information about your genes and how a living system works. It’s very, very compact and very durable,” said co-author Luis Ceze, UW associate professor of computer science and engineering, in a press release.
“We’re essentially repurposing it to store digital data, pictures, videos, documents, in a manageable way for hundreds or thousands of years.”
Digital data storage using DNA by Luis Henrique Ceze of University of Washington and… https://t.co/KUlHHMUzXspic.twitter.com/ahanCZGJqu
— Naesstrom (@Naesstrom) December 4, 2015
The team of bioengineers and computer science and electronic engineers were able to encode data from four image files into the nucleotide sequences of synthetic DNA snippets. This was achieved by converting the long strings of 1’s and 0’s in digital data into the four building blocks of the DNA sequence – adenine, guanine, cytosine and thymine. The synthesized DNA molecules were then dehydrated for long-term storage.
Miraculously, researchers then reversed the process by retrieving the correct sequence from a large pool of DNA and reconstructing the images without losing a single byte of information, according to the University of Washington.
The University of Washington and Microsoft researchers chopped up digital data and encoded it into nucleotide ... https://t.co/ZdjfTAnJrS
— Badru WISE de BîðøÑ™ (@BadruWISE) April 8, 2016
To make it easier to find the images they had encoded, researchers put the equivalent of zip codes and street addresses into the DNA sequence to facilitate easier retrieval. Researchers also used Huffman coding for lossless data compression, according to Techworm.
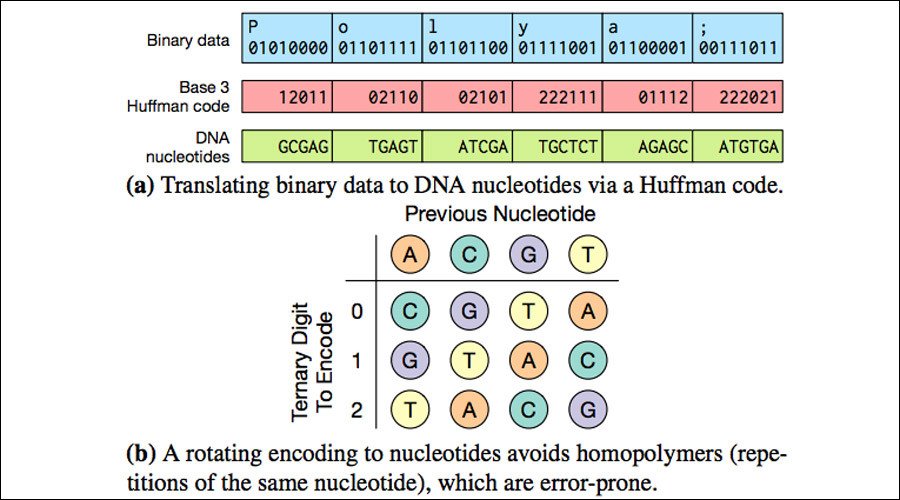
“How you go from ones and zeroes to As, Gs, Cs and Ts really matters because if you use a smart approach, you can make it very dense and you don’t get a lot of errors,” said co-author Georg Seelig, a UW associate professor of electrical engineering and computer science, said in the press release.
“If you do it wrong, you get a lot of mistakes.”
Researchers were up against a punishing deadline. The world is producing data faster than it can create new storage. The digital universe – all the data contained in computer files, historic archives, movies, photo collections, plus the exploding volume collected by businesses and devices worldwide – is expected to hit 44 trillion gigabytes by 2020, according to the UW. That’s a tenfold increase compared to 2013.
CIA teaming up with skincare line that collects DNA in unconventional wayhttps://t.co/i0I5GJqovkpic.twitter.com/tbQC9lazMZ
— RT America (@RT_America) April 8, 2016
Ceze and his team think they can go much further, moving on to store video and large digital files. They claim it could be possible to “shrink the space needed to store digital data that today would fill a Walmart supercenter down to the size of a sugar cube.”
Researchers said DNA molecules can store information many millions of times more densely than existing technology for digital storage, such as flash drives and hard drives, as well as magnetic and optical media. Those systems also degrade after a few years, while DNA can preserve information for centuries.
Scientists sue NY state police for forcing them to ‘customize’ DNA test resultshttps://t.co/fxuNpPBJV7pic.twitter.com/gpiylCGgBV
— RT America (@RT_America) February 22, 2016
The study, A DNA-based Archival Storage System, was presented at this year’s ACM International Conference on Architectural Support for Programming Languages and Operating Systems.













